In the world of industrial automation and Big Data, everything is based on data.
You have massive volumes of it, arriving at high speed, in every format imaginable, from files on a network drive (NFS) to objects in cloud storage (S3) and documents in a NoSQL database (MongoDB). This is the definition of heterogeneous data, and it’s a huge challenge. The data is isolated, “dumb,” and has no shared meaning, making it incredibly difficult to use for tasks like fault diagnosis.
For this research thesis, I focused my research on solving this issue. My work, formally titled “Prototypical Realization and Evaluation of the Data Organizaton and Management for Heterogeneous Data,” was focused on one question: Could I build a system that unifies these different data sources and gives them a shared “brain” to make them intelligently searchable?
The work was done at the Institute for Industrial Automation (IAS).
Objective
The core problem wasn’t just storing the data, it was the syntactic and semantic heterogeneity. In other words, the systems didn’t just speak different file formats, they spoke different languages about the meaning of their data.
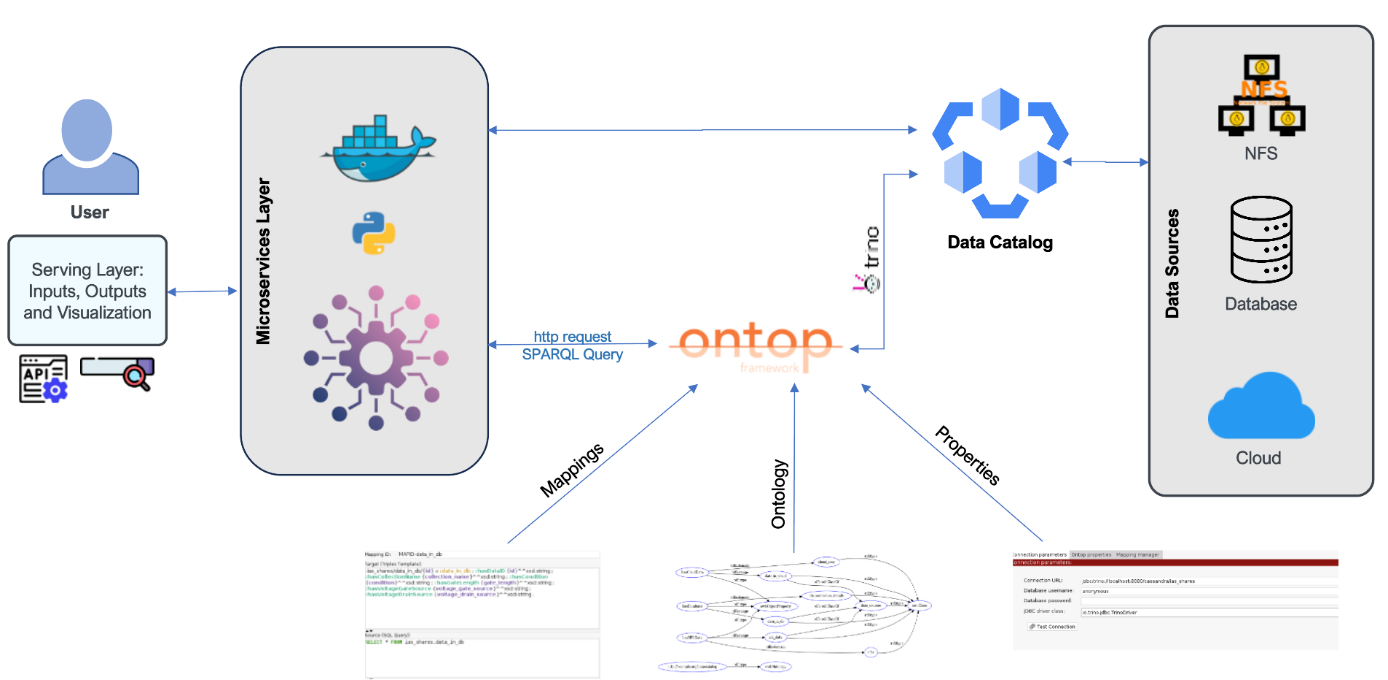
My objective was to design and build a functional prototype of a data management platform that comprises of:
- Data Catalog: Automatically index data and metadata from diverse sources (NFS, S3, MongoDB).
- Semanticize: Create a unified, formal Ontology, a model of the data’s meaning and relationships (e.g., ‘this sensor reading is a part of this manufacturing test’).
- Unify: Implement a Virtual Knowledge Graph (VKG), which connects our “dumb” data sources to that “smart” ontology, all without the costly process of moving or duplicating the data.
- Query: Allow a user to ask complex (competence) questions in a single query language (SPARQL) and get back the right data from all three sources.
My Contribution
Since this was my research thesis, I was responsible for the end-to-end design, implementation, and evaluation of this prototype. My specific contributions included:
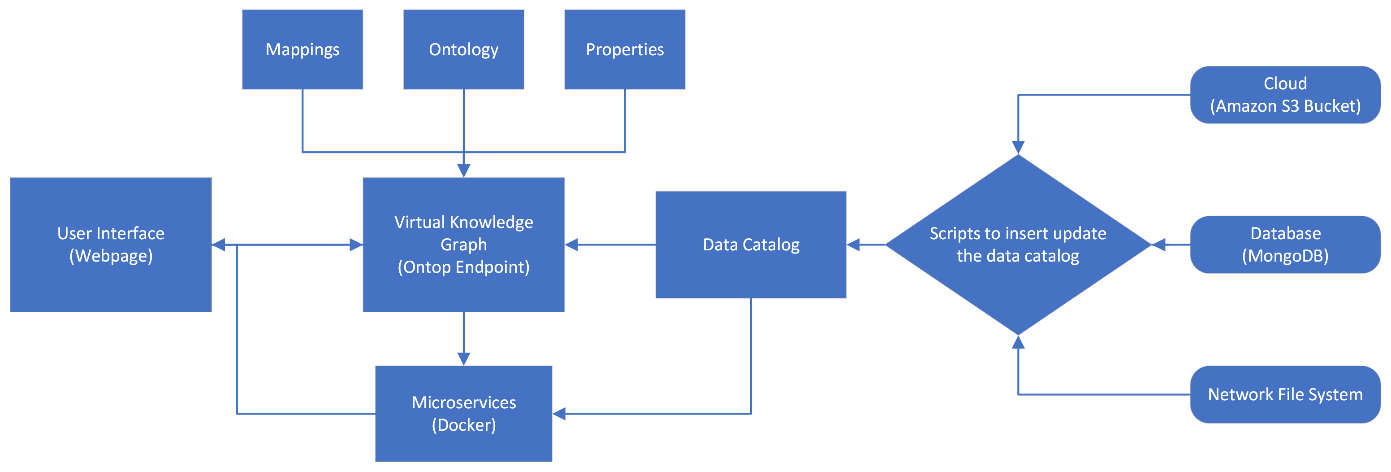
- Data Catalog Design: I built the central data catalog using Cassandra. This catalog served as the “index” or “phone book” for all data, tracking what lived where.
- Ontology Modeling: Used Protégé to develop the custom ontology, defining the classes (like ‘Sensor’) and properties (like ‘hasFrequencyData’) needed for our industrial use case.
- VKG Implementation: Used Ontop to create the Virtual Knowledge Graph. This component’s job was to translate incoming SPARQL queries (what the user wants) into the specific queries each data source understands.
- Problem Solving the “Connector”: I hit a major roadblock. Ontop couldn’t talk to Cassandra directly. As a solution, I implemented Trino (a distributed SQL query engine) as the “universal translator” to sit between them.
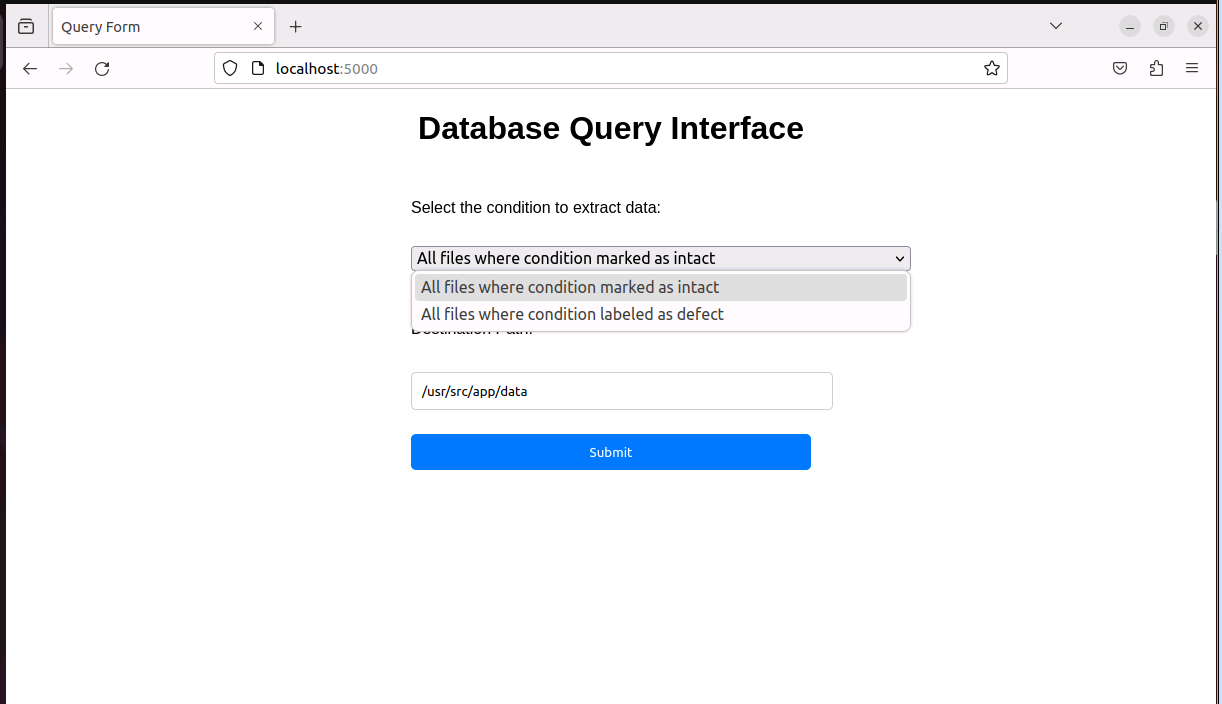
- Prototyping: I containerized the entire architecture using Docker and developed a simple front-end web UI with Python and Flask to prove the concept.
Technical Details
- Data Sources: Virtual Machines (NFS), Amazon S3 Bucket, MongoDB Cluster
- Software/Libraries: Python, Flask, Docker, Docker-Compose, Ansible
- Key Platforms: Cassandra (Data Catalog), Protégé (Ontology Editor), Ontop (VKG/OBDA System), Trino (SQL Query Engine)
- Key Concepts: Virtual Knowledge Graph (VKG), Ontology-Based Data Access (OBDA), Data Catalog, SPARQL, Heterogeneous Data, Microservice Architecture
Challenges & Learnings
The most challenging part of this project wasn’t any single component, but the integration, specifically, getting the Virtual Knowledge Graph (Ontop) to talk to the Data Catalog (Cassandra).
The “Rosetta Stone” Problem Ontop is brilliant at translating SPARQL into SQL, but Cassandra doesn’t speak traditional SQL. It speaks CQL (Cassandra Query Language) and didn’t had an integration with Ontop yet. They couldn’t communicate. This was a critical failure point.
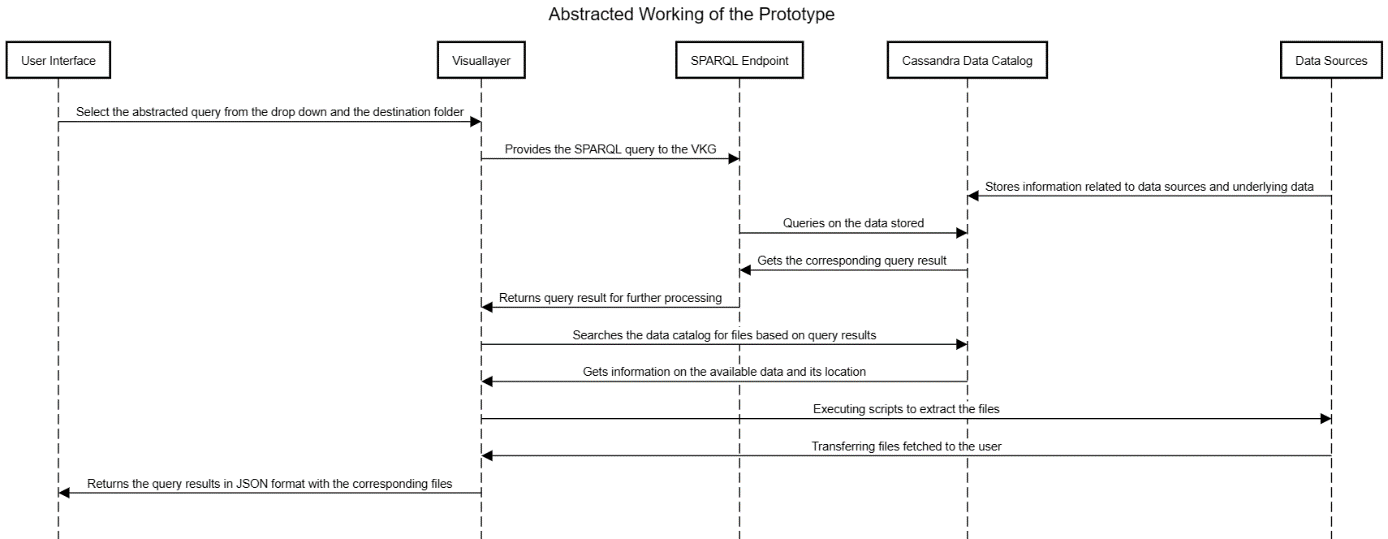
The solution was Trino. I implemented it as an intermediary. The query flow became:
- My Flask UI sends a SPARQL query to Ontop.
- Ontop translates the SPARQL query into a standard SQL query, which was based on the developed Ontology.
- Ontop sends that SQL query to Trino.
- Trino, using its Cassandra connector, translates the SQL query into a CQL query.
- Cassandra returns the data, and the chain reverses, ultimately giving me a JSON result in my UI, along with the files in the required location.
This discovery unlocked the rest of the architecture. I didn’t need a perfect, all-in-one tool. I could compose a chain of specialized tools to solve the problem.
My Key Takeaway: Virtualization > Migration The biggest lesson was the power of the Virtual Knowledge Graph (or Ontology-Based Data Access) approach. I didn’t have to build a new, multi-million dollar data warehouse and migrate everything (which is slow, expensive, and risky). Instead, I built a smart semantic layer on top of the existing, messy data sources. This approach provides huge flexibility, allowing us to add new data sources or update the business “rules” (the ontology) without re-engineering the entire data pipeline.
Further information about the project and more validation steps implemented can be seen in the Github repo.
This project proved that by combining a data catalog (to know where data is) with a VKG (to know what data is), we can successfully control the chaos of heterogeneous data.